本文章内容:使用 TypeScript 实现 Rust 的部分模式匹配特性(match、Option、Result)
标题可以理解为《 Rust 味的 TypeScript 》
阅读须知:
- 无需 Rust 基础知识,也与 Rust 最难的内存安全模型无关
- 包含对模式匹配的理解
- 包含一种实现的开源代码讲解
- 少量类型体操
模式匹配 (Pattern Matching)
是什么
模式匹配是检查给定记号序列中,是否存在某种模式的组成部分的行为。——维基
pattern matching is the act of checking a given sequence of tokens for the presence of the constituents of some pattern. —— Wikipedia
模式可以理解为【规律】。定义听起来很抽象,举一点例子之后是很容易理解这个名字的。
1
2
3
4
5
6
7
8
|
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
_ => println!("anything"),
}
}
|
最简单的使用就像一个 switch,但是除了能匹配出值,也能匹配出位置、甚至名字。
对后面这句是不是有点想法?
1
2
3
4
5
|
const { a, b } = { a: 1, b: 2 };
// a should be 1; b should be 2.
const [ a, _, ...c ] = [ 1, 2, 3, 4, 5 ];
// a should be 1; c should be [3,4,5].
|
其实js里的解构赋值就是一种模式匹配,除了【条件执行】以外,还有【提取】出想要的数据的功能。回过头看正则表达式,就能很容易理解这个概念,既可以test去测试是否匹配,又可以exec去捕获匹配到的数据。
In contrast to pattern recognition, the match usually has to be exact: “either it will or will not be a match."—— Wikipedia
在维基里还指出了模式匹配与模式识别(Pattern Recognition)的一个区别,就是前者一般来说是精确 的,要么会被匹配,要么不会被匹配(对于一个分支来说),不会有置信度多少的匹配情况。
好处在哪
符合人类思考方式的设计
比如我们现在想要计算某一个规则二维图形的周长,这个图形可能是矩形、圆形或者三角形,那么我们写代码的时候可能会这样写:
1
2
3
4
5
6
7
8
9
10
11
|
let c;
if (shape == Rectangle) {
let len, wide = shape.len, shape.wide;
c = (len + wide) * 2;
} else if (shape == Circle) {
let r = shape.r;
c = pi * r * 2;
} else if (shape == Triangle) {
let {side1, side2, side3} = shape;
c = side1 + side2 + side3;
}
|
这种代码与我们的思考方式有相悖的地方:
- 我们辨识一个二维图形的时候并不是用排除法的,我们可以一眼看出来这是什么图形,不需要一步步排除
- 这种代码需要先假设一个周长未知(即变量c)的图形,之后再进行填充,风险就是可能直到最后的 else if 都没匹配上,这样 c 就成了一个未初始化的值(Uninitialized variable),众所周知这种情况常常导致 bug / undefined behavior
因此,我们希望有一种更加阳间的写法:
1
2
3
4
5
|
let c = match shape {
Rectangle {len, wide} => (len+wide)*2,
Circle {r} => pi * r * 2,
Triangle {side1, side2, side3} => side1 + side2 + side3,
};
|
即使是没学过match语法的人应该也能看懂这样的写法,语义上可以理解为:
我们想计算c,需要对它的类型进行一次匹配,而且我们可以看出是三种类型中的一种,然后我们将从对应的类型里提取出需要的参数并进行计算(看成一个解构赋值)。
这里是否解决了上述可能导致ub的问题?答案是在编译器的帮助下,是可以的。在类型安全的规则下,我们应当知道shape的取值范围,如果有第四种图形,那么应当在某个地方(比如类型声明)上有所体现,如果不能匹配出结果,那么这条match表达式将不知道返回什么数据,应该抛出错误。
虽然感觉例子有点小刻意,但我觉得对理解模式匹配的好处很有帮助。
【条件执行】与【提取】的兼得
当然也可以用 if (a = 114514) 这样的混沌写法,但是在实践上一般是拒绝这种写法的,因为这并不是“有条件”地赋值,早已不被提倡
在上面的例子中,我们在每个判断后加上一行赋值(不加也行,但是你的成员调用将会很啰嗦),实际上是不太有额外信息量的语句,我相信优雅流畅的代码应如自然语言一样好读
在 Rust 里确实有带条件的赋值,请自行学习 if let 语法
从语句到表达式 的转变
注意甄别语句和表达式(statement vs expression)
接触过编译原理的话应该能记住区别,忘记了也不要紧,简单概括就是:
- 语句是一个过程
- 表达式是一个值
比如箭头函数() => 1,我们偶尔打顺手在1后多了个分号的时候,编译器往往会尝试纠正你,因为1;是语句,而不是表达式。
再比如我们写 jsx:
1
2
3
4
|
// valid
<div>{ condition ? 'true': 'false' }</div>
// invalid
<div> { if (condition) {'true';} else { 'false'; } } </div>
|
我想上面两段想表达的是同一个语义:如果条件成立,那么渲染 <div>true</div> ,否则渲染 <div>false</div>
但是显然下面的是非法的,因为它是一个 if 语句,而不是表达式,不具有值。
从上面举过的图形周长的例子里,我们在match后可以直接赋值给c,因此match是一个表达式而不是值
这也是跟switch的一个区别,因为switch也是一个语句而不是表达式。
表达式有比语句更灵活的特点,因为expression是statement的组成,当表达式不赋值给变量的时候我们也可以当做一个只包含一个expression的statement,这种设计有助于更优雅地编程。
性能有提升吗?
实际上模式匹配带来的是抽象层面的升华,计算机总归无法像人类一样思考,因此在性能方面并不是其优势,底层实现就是一堆 if else。
可以参考这个回答:How is match implemented in a language like Rust?
其中的回答给了这个例子:
1
2
3
4
5
6
7
8
9
10
11
|
enum Result {
SingleResult(i32),
TwoResults(i32, i32),
Error
}
match someResult {
Result::SingleResult(res) => f(res),
Result::TwoResults(res1, res2) => g(res1, res2),
Result::Error => error()
}
|
上面的 enum 是 Rust 里的枚举值,与大多语言不一样的是,Rust 的枚举值里是可以携带额外的信息的(可以是结构、数组、元组、基本类型等等)
其实现后的C代码大概如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
struct Result {
enum {
SingleResult, TwoResults, Error
} tag;
union {
struct {
int arg1;
} singleResult;
struct {
int arg1;
int arg2;
} twoResults;
} value;
};
switch(someResult.tag) {
case SingleResult: {
int res = someResult.value.singleResult.arg1;
f(res);
break;
}
case TwoResults: {
int res1 = someResult.value.twoResults.arg1;
int res2 = someResult.value.twoResults.arg2;
g(res1, res2);
break;
}
case Error: {
error();
break;
}
}
|
上面的union在TypeScript里有更为优雅的表达(缺点是没把SingleResult与{arg1: number}绑定起来):
1
2
3
4
|
interface Result {
tag: enum ResultTag { SingleResult, TwoResults, Error },
value: {arg1: number} | {arg1: number, arg2: number},
}
|
这个涉及代数数据类型(Algebraic Data Type),指可以进行代数运算的类型(比如 |,& 等),不是讲述重点,请自己查阅资料 Algebraic_data_type——wiki
Rust 的 Option, Result<T, E> 与 match
Option
1
2
3
4
|
enum Option<T> {
None,
Some(T),
}
|
尖括号很容易看出来是泛型的意思,而 Some(T) 代表一个 Some 中可以携带一个T类型的值,比如 Option 这个枚举类型包括了 None 或者 Some(i32) 两种枚举值,而 Some(114514) 就是一个Option类型。
重新思考一下上面说的携带不同类型值的 enum 的底层实现,就是那个 union,就能理解“携带值的枚举值”这件事。
一个 Option 类型的值代表其处于有值(Some)跟没值(None)的叠加态,对其进行观察(匹配)将坍塌到其中一个状态 XD
如果解析出来这个值是Some,那么我们将可以类型安全地 访问到其里面的值。(意味着编译器可以帮助你规范行为,也可以帮你做好语法提示,访问里面的值一定是类型安全的,即不会在类型上翻车)
Result<T, E>
1
2
3
4
|
enum Result<T, E> {
Ok(T),
Err(E),
}
|
我认为上面讲过 Option 后,理解 Result 应该也很简单,一个 Result 类型的值处于成功与失败的叠加态,如果成功,就能类型安全地访问其中的 T 类型但无法访问 E 类型的值(union 只能同时存在一个对吧),如果失败,我们能安全地访问错误里的 E 类型,此时又无法访问 T 类型的值。
很明显这个可以用在错误处理的领域,我觉得会很容易联想到大道至简的 go
1
2
3
4
5
|
res, err := function()
if err != nil {
// handle the error
}
use(res)
|
偶尔能见到 gopher 管自己叫 if err != nil 工程师,因为一个可能发生错误的函数往往是这么返回数据的,通过校验是否有 err 来判断成功与否,这种处理方式的缺陷除了写起来很啰嗦外,还有一个缺陷,就是处理可能不到位。
1
2
3
4
5
6
7
|
res, err := function()
if err != nil {
fmt.println("some error|", err)
// forget to return!
}
// use an invalid res!
use(res)
|
实际上,这种错误处理全凭自觉,我们将正确处理的结果与错误处理的失败原因一起返回,只能通过程序员自觉去处理这种关系,但偶尔可能在处理 err 后,忘记 return 了,而且也没对 res 进行再处理,导致执行流继续进行下去,访问了不该访问的res(此时无法知道是什么值),将会产生 ub。
而 Result 是解决这个问题的利器,因为处于成功状态的结果无法访问失败状态的类型,而失败的结果无法访问成功时的数据,即使代码还没开始跑,你也知道肯定不会出错。
常用的错误处理还有try catch系列,依然需要靠自觉,常有忘记在throwable的函数外加try,导致无法正常捕获到错误(Uncaught error)的事发生(比如对内层函数不了解的话就无法知道是否throwable,虽然常有兜底的最外层try,但是在抛出错误后却会中断执行流,无法返回到某个想回去的地方,灵活性比较低,而且写起来缩进确实不怎么好看。
🤔Promise对象与上面提到的 Option、Result 源自同样的设计思想,先占坑,在运行时再确定这个坑里应当填入啥,不同的结果状态之间是隔离的,从而做到【编译期确定的】类型安全,同时也方便更直观的链式调用,在函数式编程中,这种概念叫 Monad(单子)。
wiki-Monad
match
模式是 Rust 中特殊的语法,它用来匹配类型中的结构,无论类型是简单还是复杂。结合使用模式和 match 表达式以及其他结构可以提供更多对程序控制流的支配权。模式由如下一些内容组合而成:
- 字面值
- 解构的数组、枚举、结构体或者元组
- 变量
- 通配符
- 占位符
通过以下代码来理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.")
}
Message::Move => {
println!(
"Move in the x direction {} and in the y direction {}",
x, y
);
}
Message::Write(text) => println!("Text message: {}", text),
Message::ChangeColor(r, g, b) => println!(
"Change the color to red {}, green {}, and blue {}",
r, g, b
),
}
}
|
代码来自 模式与模式匹配 - Rust 程序设计语言 简体中文版
其实就是匹配成功后还能捕获其中的值。
Option in TS
前面讲了非常非常多的铺垫,终于到正题了,如何在 TS 里实现上面讲了一大通的这些特征?
下面的内容是对一个开源实现 oxide.ts 的源码解读 仓库地址,源码测试、文档全覆盖,堪称优雅的仓库,也很推荐阅读。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// src/common.ts
export const SymbolT = Symbol('T');
export const SymbolVal = Symbol('Val');
// src/option.ts
export type Some<T> = OptionType<T> & { [SymbolT]: true };
export type None = OptionType<never> & { [SymbolT]: false };
class OptionType<T> {
readonly [SymbolT]: boolean;
readonly [SymbolVal]: T;
constructor(val: T, some: boolean) {
this[SymbolT] = some;
this[SymbolVal] = val;
}
}
|
Option 的核心是实现一个 OptionType,而 Some 与 None 均源自 OptionType。
SymbolT 和 SymbolVal 是两个 Symbol 类型的值,意味着 OptionType 里其他的键不会与这俩发生冲突(js的类型因为使用字符串作成员名的缘故常有冲突发生的情况,比如 obj[’toString’] 就与某个内置方法冲突了)
有了 Some 和 None 类型,如何创建一个这个类型的值?通过构造函数就行了
1
2
3
4
5
6
7
8
|
export const None = Object.freeze(
new OptionType<never>(undefined as never, false)
) as None;
/// 使用 Some()
export function Some<T>(val: T): Some<T> {
return new OptionType(val, true) as Some<T>;
}
|
Tips: 变量名跟类型名是不冲突的,意味着下面的代码成立。
1
2
3
4
|
type a = number;
function a(): a {
return 1;
}
|
Object.freeze 的作用是创建一个无法增删改字段的对象
我们通过下面的方式分别创建变量

分别打印a, b,可以得到以下结果

基于Symbol(Val)和Symbol(T)这两个字段,我们可以构造出许多有用的方法,为了找一个无法静态编译期确定的例子(即运行后才知道成不成功),我先构造一个 Rusty (有 Rust 风格的)的处理函数在这。
1
2
3
4
5
6
7
|
function rustyParseInt(str: string): Option<number> {
const res = parseInt(str);
if (isNaN(res)) {
return None;
}
return Some(res);
}
|
上述函数是对 parseInt的包装,原生 parseInt 在解析失败时会返回一个 NaN,我们将NaN改成None,解析成功则返回Some
看下面的方法:
1
2
3
4
5
6
7
8
9
10
11
|
/// Option必须是一个Some,否则抛出错误(在rust里是panic)
expect(this: Option<T>, msg: string): T {
if (this[SymbolT]) {
return this[SymbolVal];
} else {
throw new Error(msg);
}
}
// example.ts
const a: number = rustyParseInt('would_fail').expect('fail_reason');
|
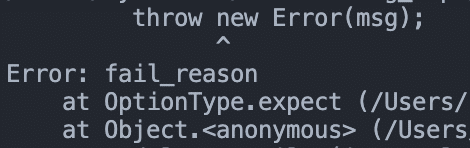
expect可以视为对【某个Option的实例应是Some】的断言,并返回其中的类型,如果不是Some将抛出错误。
运行example.ts后将会抛出理由为fail_reason的错误
由expect,又可以包装出多种方法
1
2
3
|
unwrap(this: Option<T>): T;
unwrapOr(this: Option<T>, def: T): T;
unwrapOrElse(this: Option<T>, f: () => T): T;
|
对原有 API 的安全封装
该库提供了 safe 函数,用于安全地 捕获一个同步/异步函数的结果为Option,而不会抛出错误或者引发reject。
下面截图即safe的实现代码,vscode能在then里做出正确的类型推断。
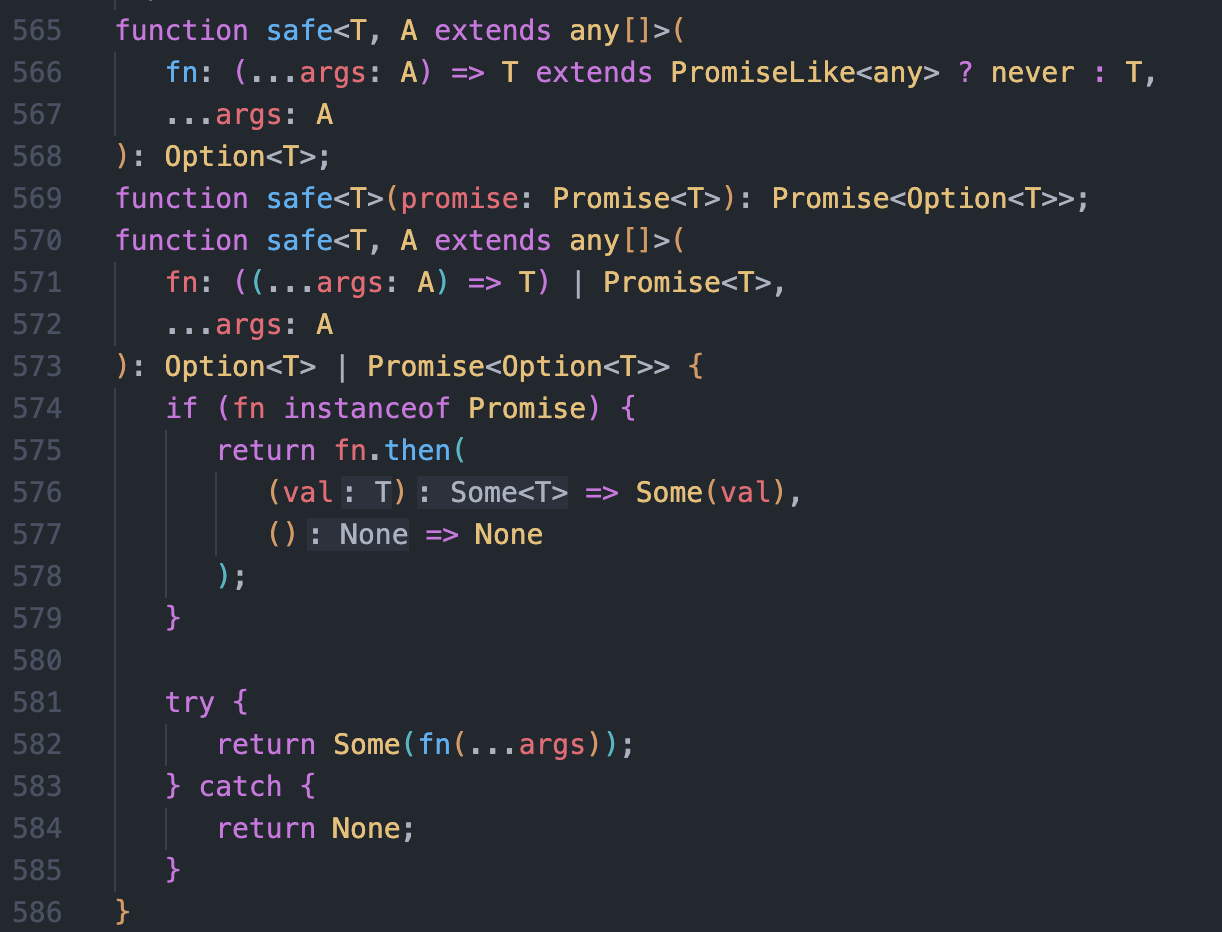
乍一看上面有三个safe,JS/TS 并不支持函数重载(Function Override),这是 TS 的 Function Overload 的特性,详见文档 functions overload。
意思是,上面两个safe是实际使用时的应当约束的函数类型,最下面的safe是对上面两种签名的兼容性实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
function makeDate(timestamp: number): Date;
function makeDate(m: number, d: number, y: number): Date;
function makeDate(mOrTimestamp: number, d?: number, y?: number): Date {
if (d !== undefined && y !== undefined) {
return new Date(y, mOrTimestamp, d);
} else {
return new Date(mOrTimestamp);
}
}
const d1 = makeDate(12345678);
const d2 = makeDate(5, 5, 5);
const d3 = makeDate(1, 3);
// No overload expects 2 arguments, but overloads do exist that expect either 1 or 3 arguments.
|
上面是官方的例子,看一下就懂了,d1, d2 都可以被正常编译,d3 则通过不了类型检查,尽管符合第三个makeDate的函数签名。
回到上面 safe 的实现(与前面是同一张图,方便观看),第一个签名接受的是一个同步函数及该函数的参数,通过 PromiseLike 来约束是否异步函数,是则要求返回值为never类型,代表一个不会返回的函数(一定会throw,或是无限循环),既然无法返回也就不会需要safe包装返回值。
一个 PromiseLike 接口要求实现 then(onfulfilled, onerjected),具体看TS的官方文档 PromiseLike 接口文档
第二个签名接受一个 Promise 对象作为参数,其实就是异步函数执行后的返回值。返回一个 Promise<Option>的结果,注意一个Option<Promise>的类型是没有实用意义的,因为不管resolve还是reject,都会得到一个Some结果,所以一个实用的包装应当是 Promise<Some>与Promise,对应了resolve与reject的结果。
实现上很简单,把 throw、reject 包装成 None, 把 resolve 和正常执行包装为 Some 即可。
其他的方法
Option 提供了一些其他的方法,实现都很简单,意义也清楚所以不详细介绍。
1
2
3
|
isNone()
isSome()
map<U>(this: Option<T>, f: (val: T) => U): Option<U>
|
Result<T, E> in TS
Result 跟 Option 的实现就没有太大差别了,除了 Result 在失败时可以携带错误信息
1
2
3
4
5
6
7
8
9
10
11
|
export type Ok<T> = ResultType<T, never>;
export type Err<E> = ResultType<never, E>;
export class ResultType<T, E> {
readonly [SymbolT]: boolean;
readonly [SymbolVal]: T | E;
constructor(val: T | E, ok: boolean) {
this[SymbolVal] = val;
this[SymbolT] = ok;
}
}
|
Ok 与 Err 的构造方式也很简单
1
2
3
4
5
6
|
export function Ok<T>(val: T): Ok<T> {
return new ResultType<T, never>(val, true);
}
export function Err<E>(val: E): Err<E> {
return new ResultType<never, E>(val, false);
}
|
match in TS
oxide.ts 对 match 的实现应该是最好玩的地方,在看如何实现之前,先看实现了怎样的功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// mapped matching
const num = Option(10);
const res = match(num, {
Some: (n) => n + 1,
_: () => 0,
});
assert.equal(res, 11);
// chained matching
function matchArr(arr: number[]): string {
return match(arr, [
[[1], "1"],
[[2, (x) => x > 10], "2, > 10"],
[[_, 6, 9, _], (a) => a.join(", ")],
() => "other",
]);
}
assert.equal(matchArr([1, 2, 3]), "1");
assert.equal(matchArr([2, 12, 6]), "2, > 10");
assert.equal(matchArr([2, 4, 6]), "other");
assert.equal(matchArr([3, 6, 9]), "other");
assert.equal(matchArr([3, 6, 9, 12]), "3, 6, 9, 12");
|
- Mapped matching 实现了对 Option / Result 的匹配,
- Chained matching 实现了更加灵活、定制化的匹配,可以匹配具体的值、也可以使用规则去匹配
实现
Match 的相关实现长下面这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
export const Default: any = () => {
throw new Error("Match failed (exhausted)");
};
export function match<T, U>(
val: T,
pattern: MappedBranches<T, U> | ChainedBranches<T, U>
): U {
return matchDispatch(val, pattern, Default);
}
function matchDispatch<T, U>(
val: T,
pattern: ChainedBranches<T, U> | MappedBranches<T, U>,
defaultBranch: DefaultBranch<U>
): U {
if (Array.isArray(pattern)) {
return matchChained(val, pattern, defaultBranch);
} else if (isObjectLike(pattern)) {
return matchMapped(val, pattern, defaultBranch);
}
throwInvalidPattern();
}
|
match接收待匹配的值跟分支的模式作为参数,然后调用 matchDispatch。
分支有mapped和chained两种,通过 isArray 和 isObjectLike 区分,然后分别进入 mapped 和 chained 的处理逻辑。
mapped
matchMapped 只支持对 Option 和 Result 进行匹配,然后对 pattern 中的项进行匹配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
function matchMapped<T, U>(
val: T,
pattern: OptionMapped<any, U> & ResultMapped<any, any, U>,
defaultBranch: DefaultBranch<U>
): U {
if (Option.is(val)) {
if (val[SymbolT]) {
if (pattern.Some) {
if (typeof pattern.Some === "function") {
// 对于 Some 类型,如果其匹配后跟的是 function,说明是对值的任意匹配
return pattern.Some(val[SymbolVal]);
} else {
// 不是function,说明可能有更进一步的匹配(具体的值、位置等等),则再次调用dispatch对值进行更细化的匹配,注意的是第三个参数defaultBranch,如果Some中提供了默认分支,那么进入,否则不进入该分支而是使用外层的默认分支(即最外层的 _: () => something)
return matchDispatch(
val[SymbolVal],
pattern.Some,
typeof pattern._ === "function" ? pattern._ : defaultBranch
);
}
}
} else if (typeof pattern.None === "function") {
// 对None匹配的处理
return pattern.None();
}
} else if (Result.is(val)) {
// 对Result分支的处理,跟Option基本相同
const Branch = val[SymbolT] ? pattern.Ok : pattern.Err;
if (Branch) {
if (typeof Branch === "function") {
return Branch(val[SymbolVal]);
} else {
// 既没在Option中匹配到也没在Result里匹配到,进入默认分支,如果提供了 _ 的匹配就执行自定义的默认分支,否则进入参数的defaultBranch
// 最上面的 defaultBranch 传入了一个会抛出异常的函数Default,即代表没有分支能处理val,这是不可接受的
return matchDispatch(
val[SymbolVal],
Branch,
typeof pattern._ === "function" ? pattern._ : defaultBranch
);
}
}
} else {
throwInvalidPattern();
}
return typeof pattern._ === "function" ? pattern._() : defaultBranch();
}
|
chained
Chained mapping 支持更加灵活的模式匹配,下面展示部分匹配的方式
1
2
3
4
5
6
7
8
9
10
|
const res = match(input, [
[1, "number"], // 匹配准确的值
[testObj, "object"], // 匹配准确的对象(浅,同一个对象才能匹配上)
["test", (val) => `string ${val}`], // 匹配准确的值,并使用函数作为Result,以捕获到 match 的 input 值
[(val) => val === true, "true"], // 提供 filter 作为匹配条件
[(val) => (val as number) > 5, (val) => `num ${val}`], // 提供 filter 为匹配条件,并使用函数作为 Result 捕获 input
[Fn(returnTrue), "fn true"], // 匹配一个函数 returnTrue,使用 Fn() 包装以跟 filter 区分开
[Fn(returnFalse), "fn false"], // 匹配一个函数 returnFalse,使用 Fn() 包装以跟 filter 区分开
() => "default", // 默认匹配,如果没法匹配到上述项将执行
]);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
type ChainedBranches<T, U> =
| Branch<T, U>[]
| [...Branch<T, U>[], DefaultBranch<U>];
function matchChained<T, U>(
val: T,
pattern: ChainedBranches<T, U>,
defaultBranch: DefaultBranch<U>
): U {
// 遍历 chianed branches,得到每个分支
for (const branch of pattern) {
// 分支允许接受函数作为分支,限定为经过 `Fn<U>` wrap 过的函数以及默认的分支 () => U
if (typeof branch === "function") {
return (branch as Fn<U>)[FnVal] ? (branch as Fn<U>)[FnVal] : branch();
} else {
const [cond, result] = branch;
// 每个分支分为条件与结果,使用 matches 判断是否匹配上了,在匹配上的情况下:
if (matches(cond, val, true)) {
if (typeof result === "function") {
// 如果结果是 `Fn<U>` wrap 过的则返回函数本身
// 结果是普通函数就执行匹配结果
return (result as Fn<U>)[FnVal]
? (result as Fn<U>)[FnVal]
: (result as (val: T) => U)(val);
} else {
// 非函数就返回数值
return result;
}
}
}
}
// 都不是则执行默认分支
return defaultBranch();
}
|
下面介绍下 Fn<U> 是做什么的:
1
2
3
4
5
6
7
|
export const FnVal = Symbol("FnVal");
export function Fn<T extends (...args: any) => any>(fn: T): () => T {
const val: any = () => throwFnCalled();
(val as any)[FnVal] = fn;
return val;
}
export type Fn<T> = { (): never; [FnVal]: T };
|
Fn 是类型也是函数,作为类型的时候表示一个无法被执行(即返回never,在实现里,一定会throw 一个错误的函数),但是存储了函数(通过 FnVal 这个 Symbol 类型来索引)的对象。
Fn 的作用是将函数包装成一个可以被匹配、可以作为匹配结果的对象,而不是在匹配成功时执行、或是作为 filter 存在,如下:
1
2
3
4
5
|
// 使用 Fn 作为分支,匹配成功将返回函数
match(Some(1), [
[Some(1), Fn(()=>"1")],
Fn(()=>'default'),
])()
|
下面介绍返回是否匹配条件的 matches 的实现:
不过先看看什么样可以算一个合理的条件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
type Branch<T, U> = [BranchCondition<T>, BranchResult<T, U>];
type BranchCondition<T> =
| Mapped<T, boolean>
| (T extends { [T]: boolean } ? MonadCondition<T> : Condition<T>);
type Condition<T> = T extends object
? { [K in keyof T]?: BranchCondition<T[K]> }
: T;
type MonadCondition<T> = T extends Option<infer U>
? Some<MonadCondition<U>> | None
: T extends Result<infer U, infer E>
? Ok<MonadCondition<U>> | Err<MonadCondition<E>>
: Wide<T>;
type MonadMapped<T, U> =
| Mapped<T, U>
| ChainedBranches<T, U>
| MappedBranches<T, U>;
type Mapped<T, U> = (val: T) => U;
type Wide<T> = T extends [...infer U] ? U[number][] : Partial<T>;
|
我们知道一个分支分成条件和结果,看 BranchCondition 即分支条件,可以是以下的情况
- Mapped,表示被准确匹配的值,比如 Some(1) 这样的
- 根据是否有 [T] 成员来区分是否 Option/Result,注意这个 T 并不是类型,而是那个 Symbol 变量
- 有 [T] 的说明是 Option 或者 Result,进入 MonadCondition
- 分别通过匹配 Option 和 Result 来确定类型
- 都不是则进入 Wide
- 如果是数组就是对数组的匹配
- 如果不是数组就是对 T 部分字段的匹配
- 没有 [T] 进入普通的条件 Condition,通过变量是否对象来分类
- 是对象的话,那么类型需要进行筛选一下,只选出需要的字段及其类型,每个字段都是一个独立的分支条件(BranchCondition)
- 不是对象的话就直接匹配该值的类型即可
Monad(单子)是前面介绍过的一个概念,简单说代表一个占坑的变量,可以是几种状态的叠加
下面则是返回是否匹配条件的 matches 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
function matches<T>(
cond: BranchCondition<T>,
val: T,
evaluate: boolean
): boolean {
if (cond === Default || cond === val) {
// 如果直接匹配上了或者是默认分支则直接返回true
return true;
}
if (typeof cond === "function") {
// 如果是被包装后的函数就判断是不是该函数,
// 否则,只有在 evaluate 为 true (代表要判断其值)时执行条件函数
return (cond as Fn<T>)[FnVal]
? (cond as Fn<T>)[FnVal] === val
: evaluate && (cond as (val: T) => boolean)(val);
}
// 如果是对象
if (isObjectLike(cond)) {
if (T in cond) {
// 如果 val 是条件的一部分,再深入判断(再次调用matches,字段级匹配)
return (
(cond as any).isLike(val) &&
matches((cond as any)[Val], (val as any)[Val], false)
);
}
if (isObjectLike(val) && Array.isArray(cond) === Array.isArray(val)) {
// 对数组匹配,元素级匹配
for (const key of Object.keys(cond)) {
if (
!(key in val) ||
!matches((cond as any)[key], (val as any)[key], evaluate)
) {
return false;
}
}
return true;
}
}
return false;
}
|
小结
- 通过把类型一层一层抽象,实现类型安全的匹配
- Chained 的匹配提供了比 mapped 更灵活的使用方式
题外
为什么只广泛在函数式编程流行
参考 Why-is-pattern-matching-prevalent-only-in-functional-programming-languages
- 模式匹配实际上和一个强大的类型系统有很强的关系,那就是代数数据类型(Algebraic Data Type),在前面简单提到过,比如 | 为传统的 union 类型提供了更强大的表达能力,& 也比复杂的继承更好写。
- 因为 C 没有
- 在一些比较新的语言里(比如 TypeScript 和 Rust)强大的类型系统就为模式匹配提供了土壤。
现在的 OO 语言也在一些比较微观的层面上引入了一些函数式编程的概念,来提高程序的表达能力,比如 Python3.10 就引入了 match,C# 也引入了match。
ECMAScript 里的进展
GitHub - tc39/proposal-pattern-matching: Pattern matching syntax for ECMAScript
还在 Proposal 阶段,提了好多年了似乎没什么进展,不过 star 还是很多的
提案中提供了类似以下的匹配方式:
1
2
3
4
5
6
7
8
9
10
|
match (res) {
when ({ status: 200, body, ...rest }): handleData(body, rest)
when ({ status, destination: url }) if (300 <= status && status < 400):
handleRedirect(url)
when ({ status: 500 }) if (!this.hasRetried): do {
retry(req);
this.hasRetried = true;
}
default: throwSomething();
}
|
实际上感觉不如前面实现的那种那种好看
总结
- 介绍了模式匹配的实现与好处:
- 符合思考方式
- 条件与赋值的兼得
- 语句到表达式的转变(表达能力的增强)
- Monad 式的类型安全错误处理
- 用 TS 实现 match:类型的一层层抽象
- 投入生产?原生的支持不够强大:编译器对分支覆盖的检查能力不足
参考